
Can We Prevent LLMs From Hallucinating?
And if not, what implications does this have for the future of AI?

Can We Prevent LLMs From Hallucinating?
Short Answer: Not entirely.
Long Answer: We’re getting there. It’s complicated. Keep reading…
Hallucinations was a foreign concept a few years ago but is fairly well known today. We have all seen the amusing examples of LLMs that generate basic historical and mathematical mistakes and if you spend a lot of time with even the best models you will experience this for yourself. Here is one such example:
The concept of hallucinations is known but based on recent conversations with professionals working in the space, I would say that both the true causes and ideal remediation steps are still not well understood. Let’s talk about the remediation steps first then circle back to the causes. Finally let’s wrap up with what this implies for the future of AI.
How to Reduce Model Hallucinations
There have been many advances made to drastically reduce hallucination rates when working with large models. Here is a run down.
Better models
As bigger and better models have become available, their accompanying technical reports generally highlight an increase in factuality (and thus a decrease in hallucinations). So this is a big part of the solution. The previous example prompt provided above “what is the world record for crossing the English channel entirely on foot?” now generates a factual response on ChatGPT, whether you use the GPT-4 or even GPT-3.5 model:

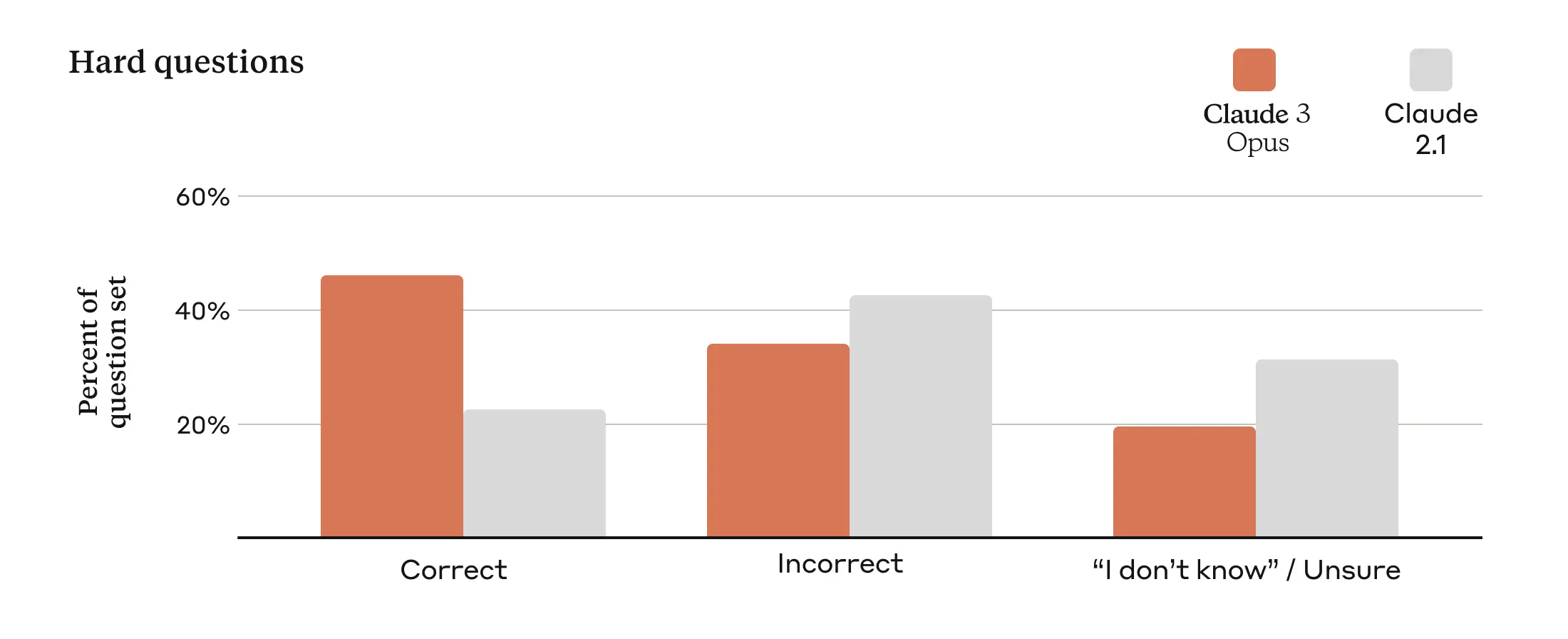
Claude 3 is a good example of a new and improved model. The “incorrect” category below can best be described as hallucinations, and you can see the improvement of Claude 3 Opus compared to Claude 2.1:
RAG (retrieval augmented generation)
RAG has one official and many unofficial implementations but the basic idea is that you take as input a user question and preform a search to locate the correct snippet of information across one or more documents. From there you inject that snippet into the context window as part of the model prompt. It’s akin to taking an open book exam, versus a non-RAG prompt which is similar to a closed book exam (and thus much harder). The process of retrieving the right snippet of information is a huge challenge and can regularly fail, even when advanced techniques such as contextual compression and re-ranking are implemented. Models may also misinterpret based on the context provided and still answer the question wrong as well.
Larger context windows
Context windows are defined as the number of tokens that a model can process as input or generate as output at once. One year ago, a typical foundation model accepted on average 8k input tokens, and this has steadily increased from 32k to 128k and even 1M+ today for certain models.
This increase in context window size can potentially allow for the ingestion of large documents as a whole, rather than as smaller segments like is typically chunked and stored in a RAG solution. One problem with this option is that recall tends to decrease as context windows increase. The paper Lost in the Middle: How Language Models Use Long Contexts highlights how position can greatly affect recall:

Others have run their own tests and have come to similar conclusions:

Improved context window recall
Newer models such as Gemini Pro 1.5 and Claude 3 have made great advances in increasing the context window size while simultaneously increasing recall rates. For use cases where it makes sense, passing an entire document into the context window on these newer models should outperform even the most advanced RAG implementations. Of course, this isn’t always practical from a cost and performance perspective, so RAG is not entirely obsolete. But the results are increasingly fantastic. Here’s a quote from the Gemini Pro 1.5 announcement:
Gemini 1.5 Pro maintains high levels of performance even as its context window increases. In the Needle In A Haystack (NIAH) evaluation, where a small piece of text containing a particular fact or statement is purposely placed within a long block of text, 1.5 Pro found the embedded text 99% of the time, in blocks of data as long as 1 million tokens.
Other types of grounding
Some ideas here would be to leverage external knowledge graphs or knowledge engines such as WolframAlpha. This is less popular than other techniques but seems to have long term merit.
Advanced prompt engineering
The way most people prompt services such as ChatGPT is to simply type in a series of statements or questions as they would ask a human. This simplicity is the key to why ChatGPT and large models in general have grown in popularity so quickly. While this can work OK in a chat interface where the user can re-prompt at will, this does not work at all for programmatic tasks that have strict consistency and accuracy requirements such as performing one step in a larger production application.
Techniques such as Few-Shot, Chain-of-Thought and ReACT have shown great improvements over basic zero-shot prompts. I would go so far to say that it’s nearly impossible to build a large model based task in production without using any advanced prompting techniques. The downside is that this type of prompting takes quite a bit of work to write and evaluate prompts, undercutting the seeming simplicity of prompting large models in the first place.
Perhaps in the future we will have more advanced structured prompting paradigms similar to {guidance} as well as more advanced automated prompt engineering builders.
Model tuning
Whether we are talking about supervised full fine tuning, supervised parameter efficient fine tuning techniques like LoRA, reinforcement learning human feedback (RLHF), or even reinforcement learning from AI feedback (RLAIF), tuning has generally shown to be an effective option for controlling model behavior but less so for improving knowledge or reducing hallucinations. At least not by itself.
Combining techniques
There is nothing stopping you from combining most, if not all, of these techniques. As one example, RAFT: A new way to teach LLMs to be better at RAG claims to improve performance by combining both RAG techniques and model tuning. Further refinements in evaluating the best way to combine these techniques should continue to result in increased improvements.
What Causes Hallucinations?
The reality is that while these techniques are super valuable, they are also imperfect because of the inherent nature of all autoregressive models such as LLMs. Autoregressive is a fancy way of saying that we are predicting the future by measuring the past. These models have no inherent logical grounding like a knowledge graph nor do they have mental models or follow classical or propositional logic rules that lead to predictable and explainable results. When a large model hallucinates, that is strictly our point of view because the model itself has no concept of factuality. It is simply predicting what is most likely to come next in a sequence.
Here’s what Yann LeCun had to say about it on Twitter:

And again more recently on the Lex Fridman podcast:
The Reliability Bar For Building Complex AI Agents
One additional insight expressed in the above video is that even highly accurate models tend to break down as you add more dependent steps as part of larger and more complex tasks. This seems obvious but worth representing mathematically.
If, for example, your model is 90% accurate across a set of tasks individually and you have a process that relies on 10 dependent tasks in sequence to complete, then the final result can be expected to be 0.9^10 accurate or less than 35% accurate. To achieve 90% end to end accuracy for a 10 task sequence requires 99% accuracy for each task!
I would like to talk more about the implications of model hallucinations and accuracy for advanced agent building but that will have to wait for a future article. For now, let’s consider a single real world example. Let’s talk about Devin AI.
Devin AI
Devin AI is pitched as the “first AI software engineer”:
With our advances in long-term reasoning and planning, Devin can plan and execute complex engineering tasks requiring thousands of decisions. Devin can recall relevant context at every step, learn over time, and fix mistakes.
We've also equipped Devin with common developer tools including the shell, code editor, and browser within a sandboxed compute environment—everything a human would need to do their work.
The technology has promise and I am sure it will improve over time. But the actual benchmarks today when you look at solving tasks end to end speak for themselves:

An improvement over prompting base foundational models for sure, but still seemingly useless at fully replacing a software engineer. Would you hire a software engineer that solves problems correctly 13.86% of the time? If you have to review every task for accuracy, how much value does this provide today?
Final Thoughts
One year ago I would have told you that because of the fundamental nature of large models, they are too difficult to reliably power complex production applications. With advances in model quality, context window sizes, context window recall accuracy, prompting techniques, grounding and more, I think we are starting to get to a point where it’s becoming much more possible.
Maybe it will take a breakthrough like the rumored Q* to get to the next phase in AI or maybe not. Yann LeCun makes excellent points, but he strikes me as a purist and the history of technology shows it is possible to build great things on top of very imperfect technology. A great example is to look at early web browsers, HTML and HTTP. All imperfect technologies but more than enough to set the foundation for the open web. These technologies beat out the information superhighway (yes, this was a separate thing before the web came to mean the same thing) that seemed to be better designed initially but never took off. As imperfect as the current wave of AI models and tools are, I think they are probably good enough to be the foundation for the next phase of AI. But I guess we’ll soon find out.