
Which LLM is the Best? Let's Build a Model Evaluation Framework and Find Out.

Evaluating LLMs
The launch of every major new LLM comes with it the argument that this model is now the best, most state of the art LLM. Model creators will make these claims based on benchmarks such as MMLU, GSM8K and HumanEval so you would think that they are impartial but a closer look will reveal that these benchmarks are far from perfect and can be gamed in any number of ways. For example, here is a view of the comparison chart published by Anthropic for the launch of Claude 3:

More impartial sources such as Chatbot Arena try to evaluate models based off of consensus i.e. wisdom of the crowd:

Even the best, most impartial benchmarks only have so much value. The truth is that no single LLM will be the best model for everything because every use case is different. Sometimes a smaller, generally less capable model is equivalent or even outperforms larger models. There’s also other factors that matter, such as cost, inference time and tuning options that might make one model impractical for a production use case.
So what’s the answer? I think the best option is for individuals to create their own evaluation process built specifically for each critical use case that they support. There are existing solutions out there, but many require the adoption of a larger proprietary service or are very complex to get started. That’s why I build BSD_Evals. Let’s dive in and understand how it works and what it can be used for.
BSD_Evals
What is it?
Today I published BSD_Evals, an open source LLM evaluation framework. BSD_Evals enables the creation of your own LLM evaluation process against popular LLM providers (Anthropic, Google, OpenAI) and cloud providers (Google Cloud). For example you could write the following prompt:
How tall is Mount Everest (rounded to the nearest meter)?
And then provide the expected answer as 8,849m. Then you specify which models you want to test and BSD_Evals will execute this prompt (or any number of prompts) against each model.
Once your evaluation process has executed you will see an evaluation summary:
Execution summary:
Total runtime: 38.158690452575684
Models: 4
Evals: 6
Total Evals: 24
Passed Evals: 12
Failed Evals: 9
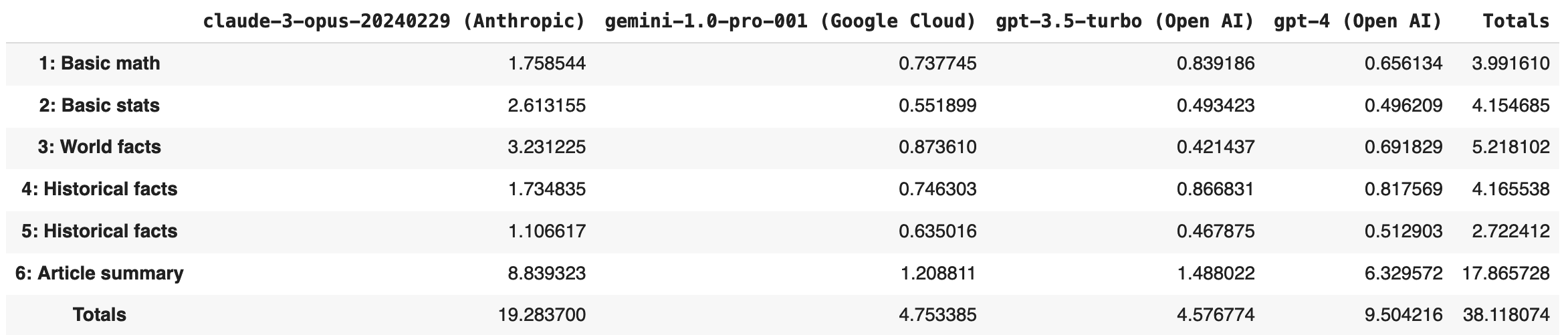
Other Evals: 3An evaluation matrix, so you can view how each model performed:

And a runtime matrix, so you can view the API response times for each model:
How do I use it?
Download the code from the repo, install it locally on your machine and follow the configuration instructions. Alternatively, run the provided notebook on Google Colab. Before running, you will want to define the models and the evaluation prompts to run for each model.
Here’s a view of how to define your models:
models = [
Model(
model_family="Claude",
model_version="claude-3-opus-20240229",
service="Anthropic"),
Model(
model_family="Gemini",
model_version="gemini-1.0-pro-001",
service="Google Cloud"),
Model(
model_family="GPT",
model_version="gpt-4",
service="Open AI")
]
And here is how to write evaluations:
[{
"description": "Basic math",
"prompt": "1+2=",
"expected_response": "3",
"eval_type": "perfect_exact_match"
},
{
"description": "Basic stats",
"prompt": "I have two red balls and two blue balls. You take one blue ball away. How many balls do I have left? Just provide a numeric digit response (no text).",
"expected_response": "3",
"eval_type": "perfect_exact_match"
}]
And that’s it! An example script has a set of models and evaluations pre-configured as well. There’s more fine grained options, such as defining model temperature, but getting started is easy.
What can I use it for?
I have already touched upon using BSD_Evals to evaluate model performance for each of your use cases. Beyond that, here are a few more ideas:
Service response time. General benchmarks do not evaluate service API response times, so this is a good way to estimate exactly what kind of response time you can expected in production with real world examples represented in your evaluation set.
Prompt engineering. Write a bunch of prompt variations and evaluate them across one or more models. BSD_Evals makes this easy.
Application monitoring. Does your production application rely on an LLM API? If so, you can schedule BSD_Evals to run periodically to quickly catch general issues affecting your production application and switch to alternatives with confidence.